La prévision des ventes est un outil essentiel pour les pilotes de stock et de flux œuvrant dans les services supply chain.
Bien que d’apparence anodine et simple, le sujet est en réalité mal compris par beaucoup. Il est fréquent que certaines notions fondamentales, comme la nature exacte d’une prévision, la façon de l’utiliser et de la construire, et de l’interpréter soient incomprises. L’intuition n’est pas toujours bonne conseillère dès lors qu’on parle de modèles mathématiques, de facteurs d’impact ou de probabilité.
Dans cette tribune, nous passons en revue 5 idées reçues sur les prévisions de ventes et leur utilisation dans la supply chain. Les concepts fondamentaux sont précisés sur la base d’exemples afin de permettre à chacun de comprendre les notions présentées et d’utiliser les prévisions de vente à bon escient et avec de bons résultats.
Idée reçue N°1 : Il est inutile de faire des prévisions de vente car elles sont toujours fausses
Avant de pouvoir affirmer qu’une prévision est fausse, il convient de bien comprendre ce qu’elle est et ce qu’elle signifie réellement. Contrairement à l’intuition, une prévision de vente, ce n’est pas un nombre égal aux ventes qui vont avoir lieu à une période donnée pour un produit donné en un lieu donné. Dans sa plus grande généralité, une prévision est une évaluation de la pondération associée à chacune des valeurs possibles pour la quantité qui sera vendue. Cette pondération s’appelle une probabilité : elle attribue un poids à chaque quantité vendue possible.
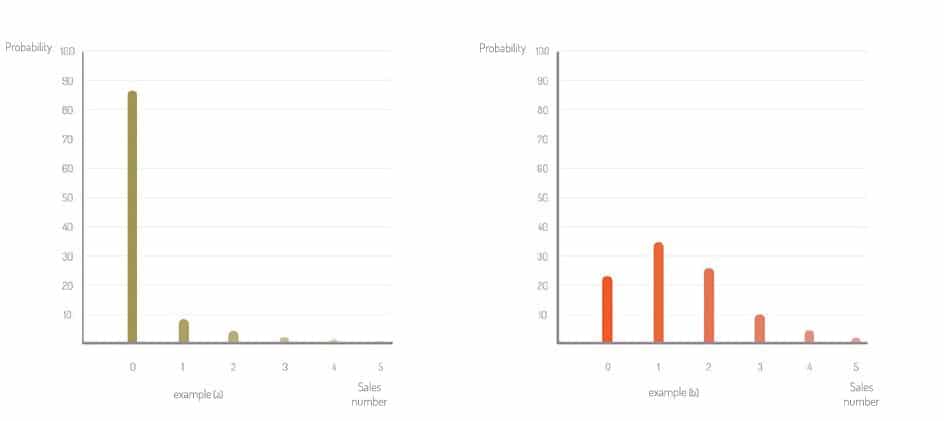
A la Figure 1 ci-dessous, on a représenté deux exemples (a) et (b) de prévisions différentes. Comme on le voit, on ne considère pas une valeur de vente possible unique, mais plusieurs valeurs, chacune pondérée par une probabilité.
Contrairement à cette vision probabiliste, qui décrit finement les possibilités futures, on trouve trop souvent la prévision de vente exprimée ou comprise comme un nombre entier unique, éventuellement associé à une mesure de l’incertitude. Dans la réalité, ce nombre est souvent la quantité vendue en moyenne (dite quantité « espérée »). Mais cette valeur moyenne n’est pas la seule valeur possible, loin de là ! A la Figure 1 (b), on voit que la valeur moyenne est de 1,40, mais la prévision indique qu’il est plutôt probable de vendre soit 0, soit 1 soit 2 quantités. La probabilité de vendre 3 ou plus est relativement faible. Dans tous les cas, la quantité vendue sera différente de la valeur espérée (égale à 1,40). Avec une lecture naïve, on conclura que la prévision est fausse !
Pour un usage d’approvisionnement, la prévision des ventes exprimée par les probabilités est celle dont nous avons réellement besoin, car elle permet de relier directement la prévision, le taux de service cible et la quantité à approvisionner. A la Figure 1, imaginons que nous voulions déterminer quelle est la quantité de stock qui garantit un taux de service d’au moins 98% (c’est-à-dire, avoir au plus un taux de 2% de rupture de stock). Dans l’exemple (a), la probabilité de vendre « 0 ou 1 ou 2 » quantités est égale à la somme des probabilités de vendre 0, de vendre 1 et de vendre 2, soit ici 98,5%. On voit donc qu’il faut avoir au moins 2 pièces en stock pour atteindre le niveau de service souhaité. Dans l’exemple (b), en suivant le même raisonnement, il faut mettre 4 pièces !
La lecture naïve des prévisions de vente ferait conclure de mettre une quantité de 1 pour l’exemple (a) et de 2 pour l’exemple (b) sur la base de la prévision de vente espérée. On voit qu’on est loin de garantir le taux de service souhaité.
Un point de vue souvent entendu est : « il est inutile de faire des prévisions de vente, elles sont trop fausses pour être utiles ». La physique nous apporte un point de vue fondamental.
Voici deux faits incontournables :
- Fait incontournable N°1 : il faut du temps pour transporter du stock d’un point A à un point B. Lorsque le stock arrive au point B pour y être utilisé, il a été envoyé plusieurs jours à plusieurs mois auparavant.
- Fait incontournable N°2 : le besoin en stock au point B est sujet à des variations de la demande, et à des contraintes logistiques.
Si l’on ne fait pas de prévisions, comment définir le stock nécessaire au point B dans le futur ? On peut voir les choses en termes de « stock de sécurité », mais on comprend que c’est un moyen de pallier l’incertitude sur la demande à servir par ce stock dans le futur. Il s’agit donc bien d’un processus de prévision, très simplifié. Mais comment procéder lorsqu’on doit calibrer le stock de sécurité au plus juste ? En synthèse, qu’on le fasse explicitement ou implicitement, consciemment ou pas, avec des outils sophistiqués ou non, on se donne toujours une vision des ventes futures et de leur incertitude associée. En d’autres mots, on fait des prévisions de vente.
Il existe aujourd’hui des méthodes de prévision de vente performantes qui permettent de réduire considérablement les stocks, de 5% à 30% voire 50% sur l’ensemble de la supply chain en réduisant les stocks de sécurité au strict nécessaire, grâce à une bonne estimation de l’incertitude. Elles fonctionnent également lorsque les ventes sont très faibles, comme nous allons le voir au point suivant.
Idée reçue N°2 : On ne peut pas prévoir quand les ventes sont très faibles
La prévision des ventes pour les articles à ventes rares ne fonctionne pas avec les méthodes statistiques traditionnelles comme les moyennes mobiles ou même plus sophistiqués (modèles ARIMA, Winter-Holt) sont inadaptées.
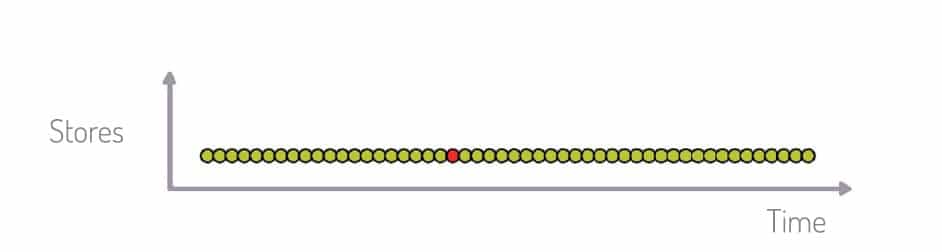
La Figure 2 représente un exemple de ventes rares. L’observation d’un article dans un magasin au cours du temps ne fournit pas assez d’information pour faire des prévisions utilisables. Par contre, à la Figure 3, si l’on observe ce même article dans plusieurs points de vente, on voit apparaître des phénomènes liés au magasin ou à la période. Cela donne des informations qui permettent d’estimer les probabilités de vente chaque jour, dans chaque magasin.

On peut encore affiner la connaissance des ventes de l’article en analysant aussi les ventes des articles « semblables », dans le même point de vente et dans les autres (figure 4). On peut alors identifier les corrélations entre toutes ces ventes, ce qui donne un échantillon consolidé statistiquement significatif.
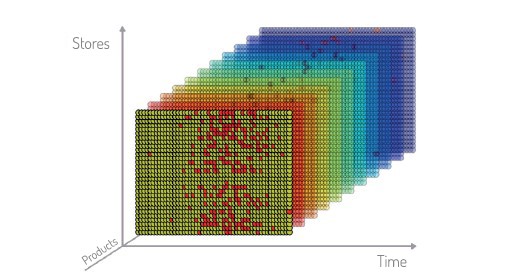
Des informations complémentaires telles que les promotions actuelles et futures, la météo, les caractéristiques intrinsèques des articles doivent également être prises en considération dans la création des prévisions. Les probabilités de vente sont générées quotidiennement pour chaque magasin et chaque article. Cela permet de calculer l’inventaire nécessaire pour garantir le taux de service souhaité à n’importe quel moment.
En ce qui concerne l’approvisionnement d’articles aux faibles ventes, une autre préoccupation est la suivante : « Pourquoi faire une prévision pour un article qui est vendu tous les deux mois ? Nous fournirons un stock d’une pièce quoi qu’il en soit ».
Si ce raisonnement est valable pour un article donné dans un magasin donné, il est erroné si l’on considère les longues périodes de temps et les points de vente multiples. Le fait d’être un « slow mover » n’est pas permanent, car pendant une promotion ou tout événement générant du trafic, un article qui se déplace lentement peut connaître une augmentation immédiate de la demande (et des ventes), nécessitant un stock supplémentaire. Le risque de manquer des ventes peut avoir un impact important, en particulier dans le secteur du luxe. Les prévisions de ventes permettent de contrôler ces variations et de passer d’un stock d’une pièce par magasin à deux ou trois pièces par magasin lorsqu’elles sont nécessaires.
En outre, une analyse approfondie des circuits et des magasins montrera que le potentiel de vente diffère entre le flagship d’Oxford Street et un petit centre commercial. Même pour un produit qui se vend rarement, certains magasins auront besoin de deux ou trois pièces alors que les autres magasins en ont besoin d’une. Comment pouvons-nous identifier spécifiquement ces magasins sans prévoir leurs ventes ?
Pour les produits à ventes rares, la prévision reste un outil d’optimisation impératif qui peut être mis en œuvre avec une approche statistique appropriée.
Idée reçue N°3 : Il y a trop de facteurs à prendre en compte pour pouvoir faire de bonnes prévisions de vente
Il y a effectivement beaucoup de facteurs à prendre en compte car les systèmes actuels archivent de très nombreuses informations : ventes quotidiennes, promotions, référentiel article détaillé, nomenclature multi-niveaux, tickets de caisse détaillés, caractéristiques magasins, etc.
Au-delà de cela, un nombre croissant de données exogènes peuvent être acquises auprès de spécialistes (météo) ou depuis l’Internet via des systèmes de crawling (avis client, blog spécialisés, tendances concurrence…).
Cette richesse de données est une chance : l’intégration et l’exploitation de ces multiples facteurs n’est maintenant plus hors d’atteinte.
Les techniques récentes sont basées sur le Machine Learning, qui permet d’écrire des programmes qui apprennent tout seuls les relations entre les variables et créent les modèles de prévision. Ils sont capables de sélectionner puis d’exploiter automatiquement les variables importantes du point de vue de la variable cible (par exemple : les ventes).
Dans ce contexte, l’utilisation de données telles que la météo pour améliorer les prévisions se fait de manière relativement transparente et ne constitue pas un challenge majeur.
Les chaines de calcul basées sur le Machine Learning sont également capables d’auto-apprentissage : elles effectuent des prévisions selon plusieurs modèles, puis apprennent à sélectionner les meilleurs d’entre eux en confrontant les prévisions effectuées avec les ventes réelles. Il y a donc amélioration automatique de la qualité au fil du temps.
Idée reçue N°4 : On a besoin d’une seule prévision de vente pour tous les usages dans l’entreprise
Dans une entreprise de distribution, différents niveaux de granularité de la prévision sont nécessaires :
- Pour définir les stocks magasin et les préparations de commande entrepôt, on va utiliser des prévisions de vente, avec une granularité à l’article, par jour et par magasin.
- Pour planifier les commandes fournisseurs pour approvisionnement des entrepôts, on utilisera des prévisions de commande à la maille article, semaine sur une durée plus longue.
On constate souvent l’utilisation de deux systèmes indépendants pour réaliser ces prévisions : l’une en aval, l’autre en amont. On constate aussi que les responsables du réseau ont des prévisions de chiffre d’affaire, le marketing à des prévisions de retour sur investissement, etc. En bref, l’entreprise regorge de modèles de prévisions déconnectés les uns des autres.
Il est donc faux de dire qu’il existe un seul besoin de prévisions ; cependant ces différents besoins ne peuvent-ils pas se déduire d’une seule prévision « fondamentale » ?
Ici également, la réponse est non. La raison essentielle est que tout processus d’agrégation ou de décomposition de prévisions fait perdre de la qualité, surtout lorsqu’il est fait un peu grossièrement.
Par exemple, éclater une prévision entrepôt par magasin en mettant des poids génériques fixes et des poids jours de la semaine forfaitaires conduit à une moyennisation inappropriée, sans compter que cela fait disparaître la notion de probabilité de vente.
On aborde là la notion d’erreur de modèle, que nous préciserons dans de prochaines publications, plus poussées d’un point de vue mathématiques et statistiques : nous parlerons de
- biais du modèle , qui caractérise ce qu’il peut espérer faire de mieux en termes de prévision
- variance du modèle, qui caractérise sa capacité à réaliser effectivement cette meilleure performance de prévision.
- De bruit, induit par la qualité des données, qui sont toujours incomplètes et partiellement erronées
Au final, on peut retenir une règle simple : c’est en général en basant les modèles directement sur les quantités d’intérêt, en limitant les manipulations intermédiaires, que l’on obtient les résultats les plus fiables. Plusieurs besoins impliquent donc bien des démarches prévisionnelles distinctes.
Cependant, il faut aussi de la cohérence : lorsque par exemple la somme des prévisions magasin sont en hausse par rapport à l’année précédente, on doit voir des évolutions à la hausse dans les prévisions de sortie des entrepôts.
Typiquement, une approche basée sur le Machine Learning va utiliser les prévisions effectuées au niveau magasin comme prédicteurs venant compléter les historiques de sortie entrepôt. Le modèle obtenu de cette manière saura établir un lien souple entre les données les plus proches du problème à résoudre (les sorties entrepôts) et la réalité du besoin prévu par les magasins.
Idée reçue N°5 : Utiliser des prévisions de vente, c’est compliqué
La meilleure prévision seule ne sert à rien si elle n’est pas utilisée correctement. Et ce n’est pas compliqué si les bonnes questions sont posées en amont !
Il est indispensable de bien définir le besoin utilisateur : quel est l’objectif métier ? Cela permettra de choisir la bonne granularité de prévision, et surtout la manière de la transformer.
Un outil d’approvisionnement performant aura été conçu en tenant compte de cela, en associant des expertises mathématiques et des expertises métier. Après avoir calculé une prévision à la granularité idéale, il tiendra compte de nombreuses contraintes (économiques, délais, merchandising, pénurie de stock, taux de service…) pour proposer un résultat répondant au besoin métier, en parlant le langage de l’utilisateur final. Selon le métier ciblé, la prévision pourra être transformée en calcul de stocks à approvisionner, en prévisions budgétaires, en recommandations de largeur d’offre, en simulation d’opérations commerciales…
Les nouvelles générations d’outils de Supply Chain sont à la fois performantes et ergonomiques, et très automatisée. Pas besoin d’avoir un doctorat en probabilité pour utiliser la prévision : elle n’est qu’une donnée intermédiaire amenant au résultat souhaité : une supply chain efficace et maîtrisée.