
"Opération Kangourou" : Comment Vekia a relancé la logistique de McDonald’s en 8 jours après une cyberattaque
Quand la crise frappe, chaque heure compte. En novembre 2024, une cyberattaque paralyse une partie du système d'information de Martin Brower, logisticien historique de McDonald’s. En huit jours, les équipes de Vekia relèvent le défi d’installer une plateforme de repli, fonctionnelle et utilisable. Ce n’est ni un miracle, ni un conte de start-up : c’est le fruit d’une gouvernance claire, d’une collaboration forte, et d’une exécution radicalement focalisée.
Une crise systémique, brutale et urgente : le choc initial et la réponse
Le 23 novembre 2024, la cyberattaque qui touche BlueYonder, un fournisseur mondial de logiciels de gestion de stocks, a des conséquences immédiates pour des milliers de points de vente. Pour Martin Brower, qui gère l’approvisionnement des restaurants McDonald’s dans plusieurs pays, l’accès à la plateforme de planification est coupé. Du jour au lendemain, impossible de calculer les besoins de chaque entrepôt, impossible de projeter les commandes.
L’impact est à la fois opérationnel et symbolique. Comme l’explique Fabien Isaert, responsable produit chez Vekia : "Le rôle de Martin Brower, c’est d’être invisible. Si le restaurant est approvisionné, tout va bien. Mais là, l’infrastructure même était menacée."
Face à cette rupture, la réaction de Martin Brower est rapide : ils sollicitent Vekia pour envisager une solution de secours, en particulier sur le marché australien qui représente plus de 1000 restaurants McDonald’s. C’est Manuel Davy, fondateur de Vekia, qui reçoit l’appel. Il connaît les enjeux, et même s’il ressent une forte envie de répondre présent, il reste lucide : "Je ne promets rien, mais on va voir ce qu’on peut faire". En interne, les équipes sont mobilisées en urgence pour évaluer le réalisme d’une telle ambition. Moins d’une heure plus tard, le verdict tombe : c’est faisable. Mais seulement si certaines conditions sont réunies.
Une infrastructure sécurisée, invisible mais décisive
Dans ce type de crise, la reconstruction rapide d’un environnement de travail opérationnel ne repose pas seulement sur les algorithmes ou les modèles métiers. Elle dépend aussi d’une couche souvent invisible, mais déterminante : l’infrastructure technique.
Thibault Devred, DevOps chez Vekia, en est convaincu. Dès les premières heures, il mobilise les outils internes d’automatisation pour mettre en service une infrastructure isolée, sécurisée, et performante. "Heureusement, nos process d'automatisation étaient déjà en place. On a pu construire un environnement propre, sécurisé et isolé en quelques heures. C’est là qu’on mesure la valeur d’une préparation invisible."
Cette réactivité n’est pas le fruit du hasard. Elle repose sur des standards internes robustes, des procédures documentées, et une culture DevOps mature. La capacité à déployer en quelques clics une infrastructure complète, chiffrée, cloisonnée, et monitorée a permis aux équipes applicatives de se concentrer immédiatement sur leur cœur de mission : la donnée et la décision.
"On parle souvent de résilience applicative, mais la vraie résilience commence dans les fondations techniques. C’est ce qu’on a expérimenté ici dans le concret", conclut Thibault Devred.
Structurer l’urgence : créer un cadre de travail à haute intensité
La première condition posée par Vekia est organisationnelle. Il faut pouvoir travailler vite, avec peu de frictions. Pas de spécifications figées, pas de validations successives, pas de couches hiérarchiques intercalées. Juste un objectif clair : produire, au plus vite, des propositions de commande fiables.
Dès le lendemain, Vekia met en place deux équipes. L’équipe "Kangourou", dirigée par Sylvain Sanahujas, data engineer senior, est dédiée au projet de secours. Elle est composée de profils seniors, capables de décider vite et d’exécuter sans friction.
En parallèle, l’équipe "Pitbull" est créée pour assurer la continuité des autres projets. Le nom est un clin d’œil assumé à leur mission : ne rien lâcher. Cette cellule veille à ce que les engagements clients soient tenus, et que l’entreprise continue de fonctionner sans chaos. Fabien Isaert le souligne : "Sans Pitbull, on aurait sauvé un client en mettant tous les autres en difficulté. Ils ont tenu la boutique pendant que nous étions en sprint."
Le cadre est volontairement resserré : présentiel imposé, interactions minimales avec l’extérieur, décision rapide, autonomie forte. Le lieu : les bureaux de Lille. Le mode opératoire : tableau blanc, post-its, to-do lists manuscrites. Pas de mail, très peu de visios. C’est un sprint. Et tout est orienté vers le court terme.
Réintégrer des données critiques et livrer vite
Sur le plan technique, la difficulté principale est claire : récupérer et traiter les données dans les délais. Stocks, ventes, historiques, commandes... Tout doit être fiabilisé et injecté rapidement.
C’est Sylvain Sanahujas, à la tête de l’équipe Kangourou, qui coordonne l’intégration. Il se souvient : "Notre premier doute, c’était : est-ce qu’ils vont pouvoir nous envoyer les flux, dans les bons formats, et rapidement ?". Heureusement : les équipes de Martin Brower sont très bien organisées. Les flux arrivent propres. Les formats sont conformes. Et surtout, la communication est fluide.
Pour aller plus vite, Vekia contourne ses outils d’intégration standards. Les traitements sont réécrits pour absorber des volumes massifs. En trois jours, la première chaîne de calcul est en place. Les premières propositions sont là. Exploitables. Et validées.
Transformer la donnée brute en décisions : un défi de data science sous contrainte
Réintégrer les données était une première étape ; leur donner du sens, en était une seconde, tout aussi critique. La valeur de l’opération Kangourou reposait sur la capacité à transformer rapidement des historiques, des stocks et des rythmes de vente en décisions de réapprovisionnement robustes.
Félix Berge, data scientist chez Vekia, a directement travaillé sur cette phase : "Notre enjeu, c’était d’utiliser les modèles existants de notre solution, en les adaptant très rapidement à une situation incomplète. Il fallait être capable d’apprendre vite, à partir de données parfois bruitées, pour faire des suggestions fiables, sans sur-ajuster".
Au lieu de chercher la perfection statistique, l’équipe a misé sur la robustesse économique : stabiliser les propositions, éviter les ruptures, et s'assurer que les décisions restaient explicables.
« Le but, ce n’était pas de prédire parfaitement, mais de proposer intelligemment », résume Félix.
Cette approche pragmatique a permis de livrer un moteur décisionnel efficace en quelques jours, capable d’évoluer au fil de la consolidation progressive des flux.
Les conditions réelles du succès
Ce succès rapide repose sur des prérequis souvent ignorés.
Premièrement, une gouvernance ultra-courte. Sylvain Sanahujas et son alter ego chez Martin Brower se parlent quotidiennement, valident, arbitrent, sans intermédiaire. Ensuite, une architecture logicielle modulaire, qui permet d’activer seulement ce qui est utile. Enfin, un client très présent, précis, impliqué. "Ils étaient hyper carrés. On avait l’impression de bosser avec nos propres équipes", confie Fabien Isaert.
Mais surtout, les équipes Vekia travaillent dans une logique incrémentale. On ne cherche pas un produit fini, on veut un outil qui fonctionne, même imparfait. Et on améliore ensuite.
L’humain dans la tempête : contenir le stress, maintenir le cap
Travailler en crise, c’est aussi résister à la surchauffe. "Le plus grand risque, c’était le surengagement. Mon rôle, c’était de freiner, pas d’accélérer", explique Manuel Davy.
La mise en présentiel joue ici un rôle fondamental. Elle permet aux équipes de se coordonner efficacement, mais aussi de se soutenir. Sylvain Sanahujas : "Quand tu franchis la porte, tu entres en mission. Mais le soir, tu ressors. Et ça change tout".
La dynamique est intense, mais contenue. Les temps de pause sont respectés. Le collectif prend le relais quand un membre fatigue. L’équipe avance, ensemble. Et le sens de la mission donne l’énergie.
Et ensuite ? Capitaliser sans figer, transmettre sans dogmatiser
Dix jours après l’appel initial, la chaîne est en production. La suite est plus classique : documentation, intégration dans la roadmap produit, ajout d’indicateurs, fiabilisation de la nomenclature (Bill of Materials).
Mais Vekia ne cherche pas à "industrialiser" le modèle. Ce qui a fonctionné ici, c’est l’exception. Il faut donc apprendre sans standardiser. Adapter sans généraliser. Et surtout, préserver l’état d’esprit : responsabilisation, focus, impact.
Une méthodologie de crise qui peut inspirer
Ce que Vekia a déployé en 8 jours n’est pas une réponse magique. Mais les principes sous-jacents sont reproductibles :
- Créer un espace-temps dédié à la résolution,
- Assumer une gouvernance ultra-courte,
- Viser un MVP fonctionnel plutôt qu’un produit parfait,
- Mettre en place des contacts humains quotidiens,
- Ne pas avoir peur d’échouer vite pour corriger vite.
"C’est la crise qui nous a permis d’être aussi rapides. Mais c’est le cadre qu’on a mis qui a permis de ne pas exploser", conclut Fabien Isaert.
Conclusion : un sprint réussi, un modèle de lucidité
L’opération Kangourou est un exemple rare de gestion de crise technologique et humaine réussie. Ce n’est pas un exploit à répéter chaque mois. C’est un rappel utile : sous pression, des équipes bien encadrées, respectées, et autonomes peuvent accomplir beaucoup.
Ce n’est pas une méthode miracle. Mais une preuve que rigueur, confiance et clarté peuvent transformer une crise en accélérateur de valeur.

Vekia et Martin Brower : une collaboration exemplaire pour assurer l'approvisionnement de secours après une cyberattaque
Communiqué
Lille, le 24 mars 2025
À la suite d'une cyberattaque ayant gravement perturbé les opérations de l'un de ses fournisseurs de logiciels SaaS pour la gestion de la chaîne d'approvisionnement, Martin Brower s'est retrouvé sans solution fonctionnelle pour gérer l'approvisionnement d'une grande chaîne de restauration rapide en Australie. Confrontée à cette situation critique, l'entreprise s'est tournée vers son autre partenaire, Vekia, spécialiste de l’optimisation des stocks et des solutions de planification avancée, afin de déployer en urgence une plateforme de secours.
En seulement 8 jours, les équipes de Vekia et de Martin Brower ont réussi à mettre en place une solution de secours entièrement configurée et prête à l’emploi. Ce déploiement rapide comprenait :
- La mise en place et la configuration de la plateforme, incluant ses algorithmes avancés.
- Le développement et l’intégration des flux de données nécessaires pour assurer une communication fluide entre les systèmes, intégrant notamment deux années d’historique des ventes.
- La création de processus complémentaires, tels que le calcul du Bill of Materials (BOM) et la gestion d’un stock perpétuel probabiliste adapté aux besoins de Martin Brower.
"Cette collaboration avec Martin Brower illustre parfaitement notre force technique et organisationnelle, qui nous a permis de répondre avec une rapidité exceptionnelle dans une situation critique tout en maintenant un haut niveau de performance et de fiabilité. Nous sommes fiers d'avoir contribué au succès de cette solution de secours pour un acteur clé de la supply chain mondiale"
Manuel DAVY, CEO de Vekia.
"Face à cette situation inédite, nous devions mobiliser un partenaire alternatif pour continuer à répondre aux besoins de notre client. Ayant déjà collaboré avec Vekia dans d’autres secteurs, nous les avons sollicités en toute confiance, sachant que leurs capacités techniques seraient à la hauteur de ce défi. Leur équipe a fait preuve d’une réactivité exceptionnelle, nous permettant de sécuriser nos opérations de secours en un temps record. Forts de cette réussite, nous explorons désormais des pistes pour améliorer encore cette solution en 2025"
Olivier Chasseloup, Global Chief Supply Chain Officer chez Martin Brower
La solution déployée par Vekia a permis à Martin Brower de :
- Assurer la continuité de l’approvisionnement de son client grâce à un plan de secours robuste.
- Optimiser la gestion des stocks durant la crise en s’appuyant sur des modèles probabilistes avancés.
- Renforcer sa résilience et anticiper les défis futurs en envisageant une potentielle industrialisation de la solution de secours.
Cette intervention réussie confirme le rôle de Vekia en tant que partenaire stratégique pour les entreprises confrontées à des défis complexes en matière de supply chain.
À propos de Vekia
Vekia est un leader en optimisation des stocks et en solutions de planification avancée, exploitant depuis 2008 des algorithmes probabilistes et l’intelligence artificielle pour aider les entreprises à relever les défis des chaînes d'approvisionnement modernes.
À propos de Martin Brower
Martin Brower est un leader mondial en logistique et en gestion de la chaîne d’approvisionnement, fournissant des solutions intégrées à certaines des plus grandes marques internationales.

5 idées reçues sur la prévision des ventes
La prévision des ventes est un outil essentiel pour les pilotes de stock et de flux œuvrant dans les services supply chain.
Bien que d’apparence anodine et simple, le sujet est en réalité mal compris par beaucoup. Il est fréquent que certaines notions fondamentales, comme la nature exacte d’une prévision, la façon de l'utiliser et de la construire, et de l’interpréter soient incomprises. L'intuition n'est pas toujours bonne conseillère dès lors qu'on parle de modèles mathématiques, de facteurs d’impact ou de probabilité.
Dans cette tribune, nous passons en revue 5 idées reçues sur les prévisions de ventes et leur utilisation dans la supply chain. Les concepts fondamentaux sont précisés sur la base d’exemples afin de permettre à chacun de comprendre les notions présentées et d’utiliser les prévisions de vente à bon escient et avec de bons résultats.
Idée reçue N°1 : Il est inutile de faire des prévisions de vente car elles sont toujours fausses
Avant de pouvoir affirmer qu’une prévision est fausse, il convient de bien comprendre ce qu’elle est et ce qu’elle signifie réellement. Contrairement à l’intuition, une prévision de vente, ce n’est pas un nombre égal aux ventes qui vont avoir lieu à une période donnée pour un produit donné en un lieu donné. Dans sa plus grande généralité, une prévision est une évaluation de la pondération associée à chacune des valeurs possibles pour la quantité qui sera vendue. Cette pondération s’appelle une probabilité : elle attribue un poids à chaque quantité vendue possible.
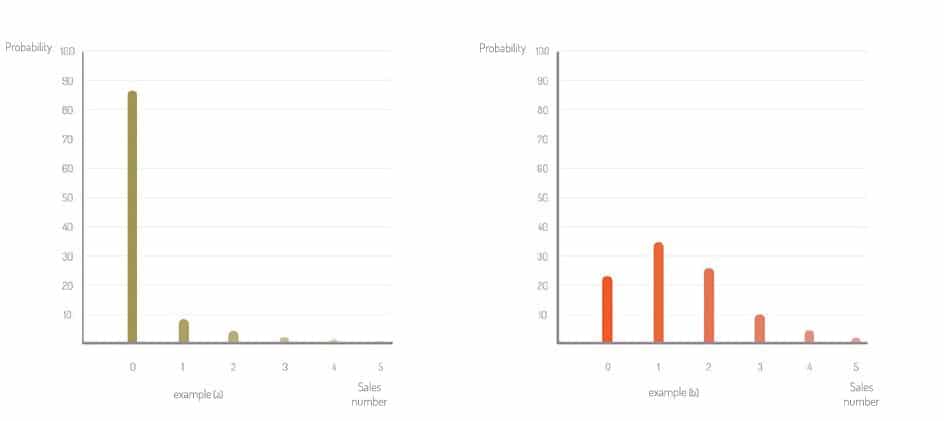
A la Figure 1 ci-dessous, on a représenté deux exemples (a) et (b) de prévisions différentes. Comme on le voit, on ne considère pas une valeur de vente possible unique, mais plusieurs valeurs, chacune pondérée par une probabilité.
Contrairement à cette vision probabiliste, qui décrit finement les possibilités futures, on trouve trop souvent la prévision de vente exprimée ou comprise comme un nombre entier unique, éventuellement associé à une mesure de l'incertitude. Dans la réalité, ce nombre est souvent la quantité vendue en moyenne (dite quantité « espérée »). Mais cette valeur moyenne n'est pas la seule valeur possible, loin de là ! A la Figure 1 (b), on voit que la valeur moyenne est de 1,40, mais la prévision indique qu'il est plutôt probable de vendre soit 0, soit 1 soit 2 quantités. La probabilité de vendre 3 ou plus est relativement faible. Dans tous les cas, la quantité vendue sera différente de la valeur espérée (égale à 1,40). Avec une lecture naïve, on conclura que la prévision est fausse !
Pour un usage d'approvisionnement, la prévision des ventes exprimée par les probabilités est celle dont nous avons réellement besoin, car elle permet de relier directement la prévision, le taux de service cible et la quantité à approvisionner. A la Figure 1, imaginons que nous voulions déterminer quelle est la quantité de stock qui garantit un taux de service d’au moins 98% (c’est-à-dire, avoir au plus un taux de 2% de rupture de stock). Dans l'exemple (a), la probabilité de vendre "0 ou 1 ou 2" quantités est égale à la somme des probabilités de vendre 0, de vendre 1 et de vendre 2, soit ici 98,5%. On voit donc qu'il faut avoir au moins 2 pièces en stock pour atteindre le niveau de service souhaité. Dans l'exemple (b), en suivant le même raisonnement, il faut mettre 4 pièces !
La lecture naïve des prévisions de vente ferait conclure de mettre une quantité de 1 pour l’exemple (a) et de 2 pour l’exemple (b) sur la base de la prévision de vente espérée. On voit qu’on est loin de garantir le taux de service souhaité.
Un point de vue souvent entendu est : « il est inutile de faire des prévisions de vente, elles sont trop fausses pour être utiles ». La physique nous apporte un point de vue fondamental.
Voici deux faits incontournables :
- Fait incontournable N°1 : il faut du temps pour transporter du stock d'un point A à un point B. Lorsque le stock arrive au point B pour y être utilisé, il a été envoyé plusieurs jours à plusieurs mois auparavant.
- Fait incontournable N°2 : le besoin en stock au point B est sujet à des variations de la demande, et à des contraintes logistiques.
Si l’on ne fait pas de prévisions, comment définir le stock nécessaire au point B dans le futur ? On peut voir les choses en termes de "stock de sécurité", mais on comprend que c'est un moyen de pallier l'incertitude sur la demande à servir par ce stock dans le futur. Il s’agit donc bien d’un processus de prévision, très simplifié. Mais comment procéder lorsqu’on doit calibrer le stock de sécurité au plus juste ? En synthèse, qu’on le fasse explicitement ou implicitement, consciemment ou pas, avec des outils sophistiqués ou non, on se donne toujours une vision des ventes futures et de leur incertitude associée. En d’autres mots, on fait des prévisions de vente.
Il existe aujourd’hui des méthodes de prévision de vente performantes qui permettent de réduire considérablement les stocks, de 5% à 30% voire 50% sur l’ensemble de la supply chain en réduisant les stocks de sécurité au strict nécessaire, grâce à une bonne estimation de l’incertitude. Elles fonctionnent également lorsque les ventes sont très faibles, comme nous allons le voir au point suivant.
Idée reçue N°2 : On ne peut pas prévoir quand les ventes sont très faibles
La prévision des ventes pour les articles à ventes rares ne fonctionne pas avec les méthodes statistiques traditionnelles comme les moyennes mobiles ou même plus sophistiqués (modèles ARIMA, Winter-Holt) sont inadaptées.
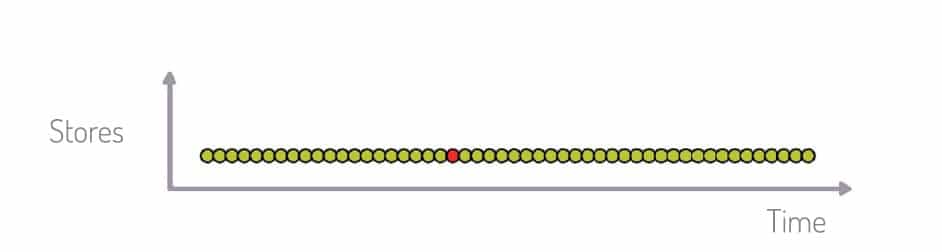
La Figure 2 représente un exemple de ventes rares. L’observation d’un article dans un magasin au cours du temps ne fournit pas assez d’information pour faire des prévisions utilisables. Par contre, à la Figure 3, si l’on observe ce même article dans plusieurs points de vente, on voit apparaître des phénomènes liés au magasin ou à la période. Cela donne des informations qui permettent d’estimer les probabilités de vente chaque jour, dans chaque magasin.

On peut encore affiner la connaissance des ventes de l’article en analysant aussi les ventes des articles « semblables », dans le même point de vente et dans les autres (figure 4). On peut alors identifier les corrélations entre toutes ces ventes, ce qui donne un échantillon consolidé statistiquement significatif.
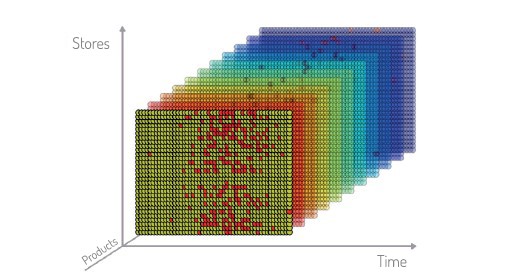
Des informations complémentaires telles que les promotions actuelles et futures, la météo, les caractéristiques intrinsèques des articles doivent également être prises en considération dans la création des prévisions. Les probabilités de vente sont générées quotidiennement pour chaque magasin et chaque article. Cela permet de calculer l'inventaire nécessaire pour garantir le taux de service souhaité à n'importe quel moment.
En ce qui concerne l'approvisionnement d'articles aux faibles ventes, une autre préoccupation est la suivante : "Pourquoi faire une prévision pour un article qui est vendu tous les deux mois ? Nous fournirons un stock d'une pièce quoi qu'il en soit".
Si ce raisonnement est valable pour un article donné dans un magasin donné, il est erroné si l'on considère les longues périodes de temps et les points de vente multiples. Le fait d'être un "slow mover" n'est pas permanent, car pendant une promotion ou tout événement générant du trafic, un article qui se déplace lentement peut connaître une augmentation immédiate de la demande (et des ventes), nécessitant un stock supplémentaire. Le risque de manquer des ventes peut avoir un impact important, en particulier dans le secteur du luxe. Les prévisions de ventes permettent de contrôler ces variations et de passer d'un stock d'une pièce par magasin à deux ou trois pièces par magasin lorsqu'elles sont nécessaires.
En outre, une analyse approfondie des circuits et des magasins montrera que le potentiel de vente diffère entre le flagship d'Oxford Street et un petit centre commercial. Même pour un produit qui se vend rarement, certains magasins auront besoin de deux ou trois pièces alors que les autres magasins en ont besoin d'une. Comment pouvons-nous identifier spécifiquement ces magasins sans prévoir leurs ventes ?
Pour les produits à ventes rares, la prévision reste un outil d'optimisation impératif qui peut être mis en œuvre avec une approche statistique appropriée.
Idée reçue N°3 : Il y a trop de facteurs à prendre en compte pour pouvoir faire de bonnes prévisions de vente
Il y a effectivement beaucoup de facteurs à prendre en compte car les systèmes actuels archivent de très nombreuses informations : ventes quotidiennes, promotions, référentiel article détaillé, nomenclature multi-niveaux, tickets de caisse détaillés, caractéristiques magasins, etc.
Au-delà de cela, un nombre croissant de données exogènes peuvent être acquises auprès de spécialistes (météo) ou depuis l’Internet via des systèmes de crawling (avis client, blog spécialisés, tendances concurrence…).
Cette richesse de données est une chance : l’intégration et l’exploitation de ces multiples facteurs n’est maintenant plus hors d’atteinte.
Les techniques récentes sont basées sur le Machine Learning, qui permet d’écrire des programmes qui apprennent tout seuls les relations entre les variables et créent les modèles de prévision. Ils sont capables de sélectionner puis d’exploiter automatiquement les variables importantes du point de vue de la variable cible (par exemple : les ventes).
Dans ce contexte, l’utilisation de données telles que la météo pour améliorer les prévisions se fait de manière relativement transparente et ne constitue pas un challenge majeur.
Les chaines de calcul basées sur le Machine Learning sont également capables d’auto-apprentissage : elles effectuent des prévisions selon plusieurs modèles, puis apprennent à sélectionner les meilleurs d’entre eux en confrontant les prévisions effectuées avec les ventes réelles. Il y a donc amélioration automatique de la qualité au fil du temps.
Idée reçue N°4 : On a besoin d’une seule prévision de vente pour tous les usages dans l’entreprise
Dans une entreprise de distribution, différents niveaux de granularité de la prévision sont nécessaires :
- Pour définir les stocks magasin et les préparations de commande entrepôt, on va utiliser des prévisions de vente, avec une granularité à l’article, par jour et par magasin.
- Pour planifier les commandes fournisseurs pour approvisionnement des entrepôts, on utilisera des prévisions de commande à la maille article, semaine sur une durée plus longue.
On constate souvent l’utilisation de deux systèmes indépendants pour réaliser ces prévisions : l’une en aval, l’autre en amont. On constate aussi que les responsables du réseau ont des prévisions de chiffre d’affaire, le marketing à des prévisions de retour sur investissement, etc. En bref, l’entreprise regorge de modèles de prévisions déconnectés les uns des autres.
Il est donc faux de dire qu’il existe un seul besoin de prévisions ; cependant ces différents besoins ne peuvent-ils pas se déduire d’une seule prévision « fondamentale » ?
Ici également, la réponse est non. La raison essentielle est que tout processus d’agrégation ou de décomposition de prévisions fait perdre de la qualité, surtout lorsqu’il est fait un peu grossièrement.
Par exemple, éclater une prévision entrepôt par magasin en mettant des poids génériques fixes et des poids jours de la semaine forfaitaires conduit à une moyennisation inappropriée, sans compter que cela fait disparaître la notion de probabilité de vente.
On aborde là la notion d’erreur de modèle, que nous préciserons dans de prochaines publications, plus poussées d’un point de vue mathématiques et statistiques : nous parlerons de
- biais du modèle , qui caractérise ce qu’il peut espérer faire de mieux en termes de prévision
- variance du modèle, qui caractérise sa capacité à réaliser effectivement cette meilleure performance de prévision.
- De bruit, induit par la qualité des données, qui sont toujours incomplètes et partiellement erronées
Au final, on peut retenir une règle simple : c’est en général en basant les modèles directement sur les quantités d’intérêt, en limitant les manipulations intermédiaires, que l’on obtient les résultats les plus fiables. Plusieurs besoins impliquent donc bien des démarches prévisionnelles distinctes.
Cependant, il faut aussi de la cohérence : lorsque par exemple la somme des prévisions magasin sont en hausse par rapport à l’année précédente, on doit voir des évolutions à la hausse dans les prévisions de sortie des entrepôts.
Typiquement, une approche basée sur le Machine Learning va utiliser les prévisions effectuées au niveau magasin comme prédicteurs venant compléter les historiques de sortie entrepôt. Le modèle obtenu de cette manière saura établir un lien souple entre les données les plus proches du problème à résoudre (les sorties entrepôts) et la réalité du besoin prévu par les magasins.
Idée reçue N°5 : Utiliser des prévisions de vente, c’est compliqué
La meilleure prévision seule ne sert à rien si elle n’est pas utilisée correctement. Et ce n’est pas compliqué si les bonnes questions sont posées en amont !
Il est indispensable de bien définir le besoin utilisateur : quel est l’objectif métier ? Cela permettra de choisir la bonne granularité de prévision, et surtout la manière de la transformer.
Un outil d’approvisionnement performant aura été conçu en tenant compte de cela, en associant des expertises mathématiques et des expertises métier. Après avoir calculé une prévision à la granularité idéale, il tiendra compte de nombreuses contraintes (économiques, délais, merchandising, pénurie de stock, taux de service…) pour proposer un résultat répondant au besoin métier, en parlant le langage de l’utilisateur final. Selon le métier ciblé, la prévision pourra être transformée en calcul de stocks à approvisionner, en prévisions budgétaires, en recommandations de largeur d’offre, en simulation d’opérations commerciales…
Les nouvelles générations d’outils de Supply Chain sont à la fois performantes et ergonomiques, et très automatisée. Pas besoin d’avoir un doctorat en probabilité pour utiliser la prévision : elle n’est qu’une donnée intermédiaire amenant au résultat souhaité : une supply chain efficace et maîtrisée.

Méthode probabiliste dans la supply chain ou comment améliorer ses prévisions

Comment les Supply Chain réalisent-elles leurs prévisions ?
Quel temps fera-t-il demain ? Combien de personne iront voire le dernier James Cameron au cinéma la semaine prochaine ? Quelle couleur sera à la mode l’année prochaine ?
Difficile de répondre avec précision à ces questions !
Pourquoi ? Parce que le propre du futur, c’est d’être incertain. En règle général, nous ne pouvons pas savoir avec certitude de quoi sera fait demain.
Mais cela ne nous empêche pas de faire des suppositions, de prendre des hypothèses, de faire des projets et de nous organiser en conséquence.
En Supply Chain, l’objectif premier est d’assurer la mise à disposition de produits, services ou ressources au moment où nous en avons besoin et dans des quantités adaptés au besoin. Comme certains délais sont incompressibles, certaines décisions doivent être prises des jours, des semaines voire des mois à l’avance.
C’est pour cela que l’une des activités cœur des SC, c’est la prévision de la demande. Tout l’enjeu est d’estimer à l’avance et le plus justement possible quelle sera la demande future, et d’en tirer les bonnes décisions !

Comment cela fonctionne-t-il ? Comment les Supply Chain réalisent-elles ses prévisions ?
Depuis des décennies, elles s’appuient sur une approche dite « déterministe » de la prévision. Une prévision déterministe est un chiffre unique considéré comme le futur le plus probable. Bien que cette vision du futur soit uniquement une hypothèse moyenne, c’est ce chiffre unique qui nourrit toute la logique d’approvisionnement : dimensionnement de stock, calcul de besoin et planification de production, de transports, dimensionnement d’équipes, etc. Tout est dimensionné pour répondre à cette vision « unique » du futur.
Parfois, cette prévision s’accompagne d’une mesure d’erreur permettant de matérialiser l’incertitude. Mais cette mesure n’est pour ainsi dire jamais exploitée dans les calculs.
Que se passe-t-il si la prévision ne se réalise pas ?
En fait, il est extrêmement rare qu’une prévision déterministe se réalise parfaitement !
On a pour ainsi dire 50% de chance d’être au-dessus et 50% d’être en dessous. Dès lors, selon l’importance l’erreur qu’on aura commise, on devra faire face soit à une pénurie soit au contraire à des surdimensionnement.
Evidemment, les professionnels de la Supply sont très au fait de cette limite majeure et ils ont très rapidement développé des palliatifs leur permettant de « limiter la casse ».
Deux cas de figure.
Lorsque la demande réelle est plus élevée que la prévision, il y a pénurie. L’outil principal dans ce cas est ce qu’on appelle le stock de sécurité. De façon simpliste, il s’agit de garder « sous le coude » un certain stock « au cas où » on en aurait besoin.
Dimensionné sur la base d’une analyse statistique de la demande et des retards de livraison passés, ces stocks de sécurité sont plus ou moins régulièrement actualisés.
Lorsque la demande est inférieure à la prévision, là, il s’agit de mettre en œuvre à posteriori et lorsque cela est possible des actions appropriées permettant d’écouler l’excédent.
Il est intéressant de noter qu’au final, seul le stock de sécurité permet, par une analyse de la variabilité de la demande passée et de la fiabilité des livraisons passées, une prise en compte partielle de l’incertitude.
Quelles sont les limites de l’approche déterministe ?
La talon d’Achille de l’approche déterministe réside dans sa vision d’un futur considéré ensuite comme certain.
En fait, dans une approche déterministe, que la demande future soit 500+/-10 ou 500+/-500 ou 500(+200/-100), l’approvisionnement restera strictement identique puisqu’il ne considère que la demande moyenne et ignore totalement l’incertitude qui l’accompagne.
La seule prise en compte de l’incertitude se fait au travers du stock de sécurité. Or, ce stock ne considère que le comportement passé, généralement sur une grande période de temps.
Si l’incertitude évolue au fil du temps, il n’en tiendra pas compte.
Si par une meilleure maitrise d’un process ou grâce à des informations plus fiables, une entreprise était en mesure de réduire l’incertitude de son futur, cela ne changerai rien à sa politique d’approvisionnement.
Si à l’inverse, à cause d’une évolution X ou Y, l’incertitude du futur devait augmenter, là encore la politique d’approvisionnement n’évoluerait en rien.
Autre limite: le stock de sécurité ne considère l’incertitude que pour la demande et le respect des dates de livraison. Or, beaucoup d’autres informations sont également incertaines. C’est le cas par exemple de la quantité à recevoir, de la qualité de la réception à venir et même des stocks courants qui sont dans la pratique plus ou moins erroné, comme en témoigne les écarts d’inventaires constatés chaque années.
Fort heureusement, il existe une nouvelle approche permettant de palier à ces limites et autorisant des prises de décisions beaucoup plus fiables.
Qu’est-ce qu’une approche probabiliste ?
Les probabilités sont le langage par excellence permettant de décrire parfaitement des informations incertaines.
Loin de se limiter au « futur le plus probable », une prévision probabiliste est une prévision décrit l’intégralité des futurs possibles, et leur chance de réalisation.
Par exemple, au lieu d’annoncer que demain il fera 20°, une prévision probabiliste énonce 0% de chance qu’il fasse 16° ou moins, 10% qu’il fasse 17°, 14% qu’il fasse 18°, 18% qu’il fasse 19%, 25% qu’il fasse 20° et ainsi de suite jusqu’à 0% qu’il fasse 25% et plus.
Sur ce principe, il est possible de parfaitement décrire l’incertitude associée à n’importe quelle information, comme une date de livraison, une quantité à recevoir, un niveau de stock, le prix de certaines ressources (matière, hr, transportation), etc.
Dès lors qu’on dispose de cette description parfaite du futur et de son incertitude, il est possible d’évaluer les différents scénario d’approvisionnement et de sélectionner celui le plus adapté: réduisant le risque, garantissant un niveau de service et/ou minimisant un coût.
On le comprend, parce qu’elle s’appuie sur une analyse exhaustive des scénarios possibles et qu’elle autorise la prise en compte de toutes les formes d’incertitudes, l’approche probabiliste permet une prise de décision parfaitement éclairée là où l’approche déterministe ne tient compte que l’incertitude qu’imparfaitement et de façon incomplète.
Passer d’une approche déterministe à une approche probabiliste. Quel chemin pour quels apports ?
Une récente étude réalisée par Vekia (à paraître prochainement) sur la base du dataset de la competition M5 démontre que, pour une même forecast, le passage de déterministe à probabiliste entraîne une réduction des couts de SC moyen de 53%.
Passer du déterministe au probabiliste représente une transformation profonde des pratiques, outils et process liés à la génération d’une prévision et la consommation de celle-ci. Il s’agit désormais de manipuler des probabilités là où auparavant on manipuler un futur probable.
La 4ème génération d’APS, aujourd’hui disponible de façon robuste et à l’échelle, permet d’effacer ses limites en proposant un module simple de mise en œuvre comme d’usage et compatible avec les ERP existants.

Comment la RSE transforme la supply chain : enjeux et bonnes pratiques
Schématisée pour la première fois dans les années soixante, la RSE (Responsabilité Sociétale des Entreprises) n’est pas un concept nouveau. Cependant, depuis la publication de la loi sur les Nouvelles Régulations Economiques en 2001, puis la loi Grenelle 2 en 2010, cet enjeu n’a cessé de prendre de l’ampleur dans les stratégies des entreprises. Aujourd’hui, 100% des entreprises françaises du CAC 40 intègrent une démarche RSE dans leur stratégie. La responsabilité de l'entreprise n'est pas réservée à la Direction RSE et la Supply Chain en est même certainement un des vecteurs les plus importants.
Aujourd’hui, proposer le meilleur service au client en maîtrisant ses coûts ne suffit plus. Il est devenu aussi primordial qu’urgent d’y ajouter le respect de l’environnement et de l’humain. Au-delà des bénéfices évidents pour l’humain et l’environnement, une dynamique de RSE au sein de votre Supply Chain peut présenter des avantages en termes de RH et d’image de marque, sans pour autant être une nouvelle source de coûts.
Alors comment l’optimisation des stocks et l’automatisation des approvisionnements servent-elles une Supply Chain orientée RSE ?
Nouveaux enjeux, nouvelles valeurs, nouvelles finalités
L’optimisation des stocks est un objectif évident dans la Supply Chain. On ne vous apprend rien, trop de stocks est synonyme d’augmentation du capital immobilisé, de plus de besoin de surfaces de stockage, plus d’invendus donc moins de marges, et plus de tension sur votre Supply Chain. Au contraire, pas assez de stock et vous risquez les ruptures, ce qui est néfaste pour la satisfaction client et réduit le chiffre d’affaires.
Ce sont les conséquences évidentes et reconnues d’une mauvaise gestion de stock. Pourtant, d’autres impacts existent. Il s’agit, comme vous l’avez compris, des impacts écologiques et environnementaux.
En général, en tant que décideur d’une organisation, notre culture, notre esprit cartésien et la pression qui pèse sur nos épaules nous poussent à considérer les enjeux financiers en premier lieu. C’est évidemment compréhensible et tout à fait louable : la santé financière de notre entreprise est la base d’un environnement sain pour tous les salariés, et le fondement de notre capacité à investir pour innover et nous améliorer.
C’est à la rencontre de ces aspirations que l’optimisation des stocks se place. Cette discipline favorise à la fois vos enjeux financiers, mais vous inscrit également dans une dynamique d’amélioration (et c’est d’autant plus vrai avec l’utilisation de technologies auto-apprenantes).
Venons-en aux faits. Comme la célèbre formule nous le rappelle, un stock optimisé à la perfection est un stock qui se trouve au bon endroit, au bon moment, et dans les bonnes quantités. Derrière ces mots simples se cache une prouesse complexe, dont on ne peut imaginer la réalisation que depuis quelques années grâce aux avancées en termes d’Intelligence Artificielle.
Car pour y arriver, on doit approcher le plus finement possible la demande future, et donc la prévoir. Si beaucoup d’entreprises ont fait le choix de simplifier cette étape jusqu’ici par un travail humain, la multiplication des canaux et l’élargissement général de l’offre font que l’Intelligence Artificielle est désormais la seule réelle solution efficace.
En parvenant à accomplir cette fameuse prouesse, vous serez en mesure d’observer plusieurs bénéfices environnementaux.
Prévoir et optimiser : un win-win pour votre Supply Chain et l’environnement
D’abord, l’optimisation des stocks rationalise votre production (ou celle de vos fournisseurs). Connaître avec plus d’exactitude les quantités à répartir vous permettra de mieux anticiper le volume de production et la prise en compte des délais. Résultat, la production est lissée et sujette à moins de périodes de rushs et de tension. De plus, si vous observiez bon nombre de surstocks, vous pourrez réduire votre production, et votre impact écologique par extension.
L’étape de production n’est pas la seule à profiter de cette réduction des surstocks au niveau environnemental. En minimisant le stock invendu, vous réduisez également la quantité de produits à recycler, voire détruire. Car si les différentes initiatives de logistique inversée et de recyclage sont une bonne chose, le mieux reste de ne pas avoir à y recourir en ne produisant tout simplement pas à outrance. La réduction des surstocks influe donc à la fois dès la production, à la toute fin de la chaîne logistique… Et aussi entre les deux !
En effet, qui dit moins de stock à distribuer sur l’ensemble de votre réseau, dit moins de surfaces de stockage à mobiliser et entretenir. Un bon point à la fois pour réduire vos coûts logistiques et contre la bétonisation de notre territoire.
De plus, les moyens de transport à engager seront moindres… Restons honnêtes, ce n’est vrai que si le taux de remplissage n’en pâtit pas. Par exemple, si le stock en chargement baisse, mais pas le nombre de véhicules routiers, le bénéfice écologique n’en sera que minime. C’est là, qu’en parallèle de l’optimisation des stocks, l’automatisation des approvisionnements entre en scène.
Une solution d’automatisation des approvisionnements comme Vekia prend en compte l’ensemble des contraintes logistiques et détermine automatiquement le meilleur approvisionnement à opérer pour couvrir la demande tout en optimisant le nombre de commandes, et donc, le transport.
En bref, en couplant un stock et un approvisionnement optimisés, vous produirez/achèterez moins, commanderez moins, et gâcherez moins, tout en maintenant voire augmentant votre disponibilité. Un projet gagnant pour votre entreprise, et gagnant pour l’environnement.
L’humain, le troisième gagnant dans les démarches RSE
Quand on parle de transformation du métier, l’automatisation des approvisionnements est un cas d’école. Une avancée comme celle-ci révolutionne la manière dont la Supply Chain est pilotée. Voyons sous quels axes l’automatisation des approvisionnements peut améliorer le métier d’approvisionneur.
Les principaux avantages de l’automatisation concernent les performances de la Supply Chain, grâce à des décisions éclairées par toutes les contraintes logistiques. Mais elle présente aussi des avantages pour les équipes auxquelles elle vient en aide.
D’abord, en les déchargeant des actions répétitives qui composent leur métier. Aujourd’hui encore, beaucoup d’entreprises fonctionnent avec des tableurs pour piloter leurs stocks et leurs approvisionnements. En plus d’être un réel poids pour l’efficacité Supply Chain, cette manière de fonctionner est à l’encontre totale de l’épanouissement et du bien-être de l’approvisionneur :
- Le quotidien est composé de gestes répétitifs et d’actions rébarbatives ;
- Soumis à la fatigue et la lassitude, l’humain perd de l’intérêt et commet des biais cognitifs qui nuisent à la qualité de son travail ;
- Il n’a pas de visibilité sur les performances de ses actions et ne sait pas sur quoi agir pour s’améliorer ;
Une solution d’automatisation des approvisionnements vient appuyer l’approvisionneur dans son métier en le libérant de ces actions, tout en lui laissant le contrôle sur la décision finale. Il peut alors continuer de piloter sans perte de temps.
Ce temps, il peut l’utiliser pour mieux communiquer avec son équipe, ses partenaires, ou ses fournisseurs. Il peut également mieux analyser les performances Supply Chain déceler les anomalies plus rapidement, et trouver des pistes d’améliorations.
D’autre part, des avantages en entrepôt sont également visibles. En réduisant le stock et en prévoyant plus en amont les commandes, la tension en entrepôt est en baisse. Les périodes de rushs sont moins nombreuses, les quantités à manipuler sont plus restreintes.
Supply Chain et RSE
La RSE est un très large sujet lorsque l’on travaille dans la Supply Chain. Si certains axes d’améliorations sont indéniablement des sources de coûts supplémentaires, l’optimisation des stocks et l’automatisation des approvisionnements présentent des avantages sur tous les tableaux. Les entreprises qui franchissent ce pas dès aujourd’hui sont celles qui seront prêtes le plus tôt à prendre en main le futur de leur Supply Chain, que l’on parle des performances, de l’humain, ou de l’environnement.

Impact-based forecast : 10 raisons d'implémenter la nouvelle génération de métriques orientées « business »
Par Johann Robette, Supply Chain Expert @ Vekia
Comment mesurer la performance de la supply chain ?
De nombreuses et importantes décisions de nos entreprises sont basées sur une forme ou une autre de prévision : décision d’embauche, de développement d’une nouvelle ligne de produits, de développement sur un nouveau territoire… . Et bien évidemment, la prévision intervient fortement dans le quotidien de nos Supply Chain.
Le rôle du prévisionniste dans l’organisation
De façon intéressante, la nécessité de prédire est si critique et requiert une telle expertise, qu’on en a fait un métier : prévisionniste.
En fait, on a créé puis spécialisé ce savoir-faire autour de fonctions dédiées, d’équipes dédiées, et même parfois de départements entiers dédiés à la prévision.
Cette organisation de la fonction prévision dans l’entreprise a quelques mérites, notamment de réunir les experts de ce sujet dans des équipes où ils peuvent partager leurs pratiques. On voit également souvent des équipes de prévisionnistes dans les départements supply chain.
Pourtant, cette séparation des tâches pose un problème clé : en séparant la fonction « prévision » de la fonction « prise de décision », beaucoup d’entreprises ont, en quelque sorte, créé des silos dans leur organisation et des décisions conduisant à des résultats en dessous de leur potentiel.
La contribution de la prévision au résultat final est complexe à mesurer
Voici pourquoi bien qu’étant un maillon clé de la prise de décision, d’autres éléments entrent en ligne de compte, souvent sous forme de contraintes et d’autres variables à prendre en compte. De ce fait, il est souvent complexe de mesurer précisément la contribution de la prévision au résultat final, à savoir l’effet de la décision prise.
Par exemple, au moment de décider d’acheter du stock d’un produit consommable à un fournisseur, la prévision de consommation est évidemment prise en compte, mais aussi le packaging (commandable par combien ?), les éventuels minima de commande ou de franco de port, le délai, etc.
Tout le monde a conscience de la valeur importante de la fonction prévision, mais son impact réel est souvent difficile – voire impossible – à mesurer.
L’enjeu c’est de trouver les métriques de la prévision
Pour autant, tous les prévisionnistes évaluent régulièrement la fiabilité de leurs prévisions, de nombreuses formules existent pour cela. Ces métriques se concentrent principalement sur la qualité intrinsèque de la prévision produite, métriques généralement nommées « Forecast Accuracy ».
Elles laissent bien souvent de côté la mesure de l’impact de la décision prise sur la base de la prévision, ce qui conduit à des décisions de moindre qualité.
Ce constat, nous l’avons fait chez Vekia depuis pas mal de temps. Et nous ne sommes pas les seuls à l’avoir fait.
Nous nous sommes donc naturellement posé la question suivante : comment évaluer la qualité d’une prévision de sorte que les décisions qu’elle conduit à prendre soient les meilleurs possibles ? dit autrement, qu’est-ce qu’une bonne prévision ?
Qu’est-ce qu’une bonne prévision ?
Pour comprendre ce qu’est une bonne prévision, il est nécessaire de revenir à la finalité de la prévision : dans quel processus de décision interviendra-t-elle ? quelle place prendra-t-elle dans la décision ?
Fondamentaux de la fonction prévision
Rappelons brièvement l’état de l’art et les fondamentaux de la fonction prévision :
La définition de ce qu’est la prévision idéale est largement partagée : c’est une prévision qui se réalise parfaitement. Exemple : « la prévision annonce a priori 996, le constat a posteriori est bien de 996. La prévision est parfaite ! »
Il est toutefois évident qu’en dépit de tous les efforts, l’avenir n’est quasiment jamais connu avec une telle certitude. Par conséquent, pour mesurer la qualité d’une prévision, la pratique consiste à en mesurer l’erreur a posteriori .
Exemple : « la prévision annonce a priori 996, le constat a posteriori est de 900. La prévision a fait une erreur de 96. »
Cette mesure d’erreur est rendue possible par une douzaine de métriques différentes de « Forecast Accuracy » auxquelles s’ajoutent d’innombrables variantes développées par les entreprises pour leurs besoins spécifiques.
La mission première de la fonction prévision est de générer des prévisions minimisant cette erreur.
La meilleure prévision est celle qui permet de prendre les meilleures décisions
Hélas, cette approche, renforcée par des décennies de pratique, laisse de côté un point essentiel: le but de la fonction prévision n’est pas de fournir la meilleure prévision qui soit ! Son but est de fournir la meilleure prévision pour l’usage spécifique des fonctions qui la consomme.
La meilleure prévision n’est donc pas la prévision parfaite, mais celle qui permet de prendre les meilleures décisions. La mission des prévisionnistes ne doit donc pas être de minimiser l’erreur entre une prévision et sa réalisation, mais bien de minimiser l’erreur des décisions qu’elle engendre.
Prenons un exemple : Imaginons un process de décision très simple, tiré de la vie quotidienne : tous les soirs, un individu consulte les prévisions météorologiques pour décider ou non de prendre son parapluie le lendemain.
Si on s’intéresse à l’erreur de prévision, alors lorsque les prévisions n’annoncent pas de pluie et qu’effectivement il ne pleut pas le lendemain, la prévision est parfaite. A l’inverse, lorsque les prévisions annoncent 10mm de précipitations et qu’en finalité, on constate 30mm, l’erreur de prévision est cette fois importante. On passe du simple au triple.
Ce qu’on mesure ici, c’est l’erreur intrinsèque de prévision.
Pour autant, dans le contexte spécifique du process de décision « parapluie ou pas », l’erreur constatée n’aura eu aucun impact sur la décision prise. Dans les deux cas, la prévision aura conduit à la bonne décision. Au regard de son usage, cette prévision était donc parfaite.
Ainsi, la qualité d’une prévision est totalement dépendante de son usage et de la pertinence des décisions qu’elle autorise.
Pourtant, comme nous l’avons vu, la fonction prévision ne dispose que de métrique mesurant la précision intrinsèque de la prévision. Aucune d’entre elles ne tient compte de son usage réel.
Cela ne signifie pas que ces métriques ne présentent aucun intérêt, loin de là. Mais force est de reconnaître qu’elles ne sont pas les plus utiles aux prises de décision de l’entreprise…
Vers une nouvelle génération de métrique « impact-based forecast »
Fort heureusement, il est tout à fait possible d’aborder différemment la qualité d’une prévision. Pour cela, il faut introduire une nouvelle génération de métriques, nommé « Forecast Impact » (et noté « FI ») qui se concentre, non plus sur l’erreur intrinsèque mais sur la qualité des décisions prises.
Construire un double digital
L’approche proposée consiste à créer un modèle informatique (ou « digital twin ») permettant d’évaluer les impacts « business » de n’importe quelle prévision fournie en entrée.
Pour construire ce double digital, il est nécessaire avant tout de modéliser le process de décision, et de définir ensuite une fonction évaluant la pertinence des décisions prises.
La pertinence des décisions prise peut être exprimé dans de très nombreuses façons. Néanmoins, par expérience, l’expression du coût financier de ces décisions démultiplie les usages possibles, comme nous l’aborderons dans la suite.
Factuellement, une modélisation parfaite des process et impacts sera parfois difficile, voire impossible à obtenir. Mais un modèle simplifié parvient souvent à « approximer » très efficacement une réalité bien plus complexe.
Le double digital ainsi créé permet donc de simuler, à partir d’une prévision fournie en entrée, tout le process de décision et d’évaluer automatiquement le coût de la décision finalement prise.
Trois typologies de prévisions
Trois typologies de prévisions vont permettre de générer les nouvelles métriques proposées et d’en démontrer toute la valeur :
· La prévision dite « actuelle », fruit du process de prévision en place. Elle permet de mesurer la Forecast Impact d’indice « a », noté « FIa ».
· La prévision dite « naïve », c’est-à-dire la prévision simple qui serait naturellement utilisée si la fonction prévision n’existait pas dans l’entreprise. Elle permet de mesurer la Forecast Impact d’indice « n », noté « FIn ».
· La prévision dite « oracle », c’est-à-dire la prévision parfaite, générée à posteriori et correspondant aux constats eux-mêmes. Elle permet de mesurer la Forecast Impact d’indice « o », noté « FIo ».
La première métrique, notée « FIn-a », est obtenue par la mesure de la différence entre le coût « FIn » de la prévision « naïve » et celui « FIa » de la prévision « actuelle ». Cette métrique s’appuie donc totalement sur le concept de FVA (Forecast Value Add) qu’elle vient booster pour mettre en évidence la valeur ajoutée, financièrement, de la fonction prévision.
La seconde métrique notée « FIa-o », est obtenue par la mesure de la différence entre le coût « FIa » de la prévision « actuelle » et celui « FIo » de la prévision « oracle ». Cette métrique estime le potentiel de gain adressable au travers de l’amélioration de la prévision.
La troisième métrique notée « FIn-o », est obtenue par la mesure de la différence entre le coût « FIn » de la prévision « naïve » et celui « FIo » de la prévision « oracle ». Cette métrique définie en quelque sorte le terrain de jeu complet, adressable au travers de l’amélioration de la prévision.
Combinées, ces métriques peuvent aisément être restituées, analysées et interprétées au travers de représentations graphiques comme des barres/aires empilées ou encore des jauges.
10 perspectives inédites
Cette nouvelle famille de métriques « Forecast Impact » ouvre de toutes nouvelles perspectives, comme en témoignent les quelques cas d’usage suivants.
De nouveaux cas d’usage
La fonction prévision est la première à tirer bénéfice de ces métriques. En effet, elles lui permettent entre autres :
1) de savoir précisément quand s’arrêter.
2) à l’inverse de savoir quel périmètre nécessite un effort accru.
3) de résoudre l’ambiguïté générée par les métriques classiques de Forecast Accuracy qui se contredisent régulièrement.
4) de sélectionner les modèles produisant les prévisions les plus adaptée à l’usage.
5) de cartographier les gisements de valeurs.
6) de prioriser les travaux les uns par rapport aux autres.
7) de mettre en évidence la contribution de chaque participant au process de prévision.
Des métriques qui bénéficient à toute l’entreprise
Mais la valeur générée par ces métriques bénéficie largement à l’entreprise tout entière :
1) intelligible de tous, elles autorisent une communication bien plus fluide que les métriques de Forecast Accuracy.
2) elles démontrent l’apport de valeur de la fonction prévision.
3) plus que de pures métriques de prévision, elles mettent en évidence les coûts inhérents aux process de décision et par la même pointent les axes d’amélioration souhaitables, etc.
Conclusion
Chaque entreprise est engagée au quotidien dans une lutte permanente contre inefficiences. Identifiés de longues dates comme tels, les silos sont souvent perçus comme autant de fracture au sein des organisations.
La fonction prévision, quant à elle, bénéficie naturellement de sa position centrale au sein de l’entreprise. Interlocuteur clé de nombreux départements, elle est au cœur même de process d’entreprise clés tel que IBF ou S&OP.
Pour autant, la mesure de la performance reste historiquement et étonnamment décorrélée dans la pratique des usages et impacts business des prévisions.
Réintégrer la dimension business dans la mesure de la prévision
La nouvelle famille de métriques « Forecast Impact » permet quant à elle de réintégrer cette dimension « business » au cœur même de la planification. Toute l’entreprise s’en trouve réalignée autour d’enjeux communs, partagés et compris de tous.
De plus, ces métriques ouvrent de nouvelles perspectives et autorisent des cas d’usage totalement inédits autour de l’automatisation, de la priorisation et de la valorisation des process clés des entreprises.
Cette approche est au coeur de notre stratégie chez Vekia
Ces métriques sont employées depuis plusieurs mois déjà par Vekia, avec un apport de valeur important constaté dans les nombreux contextes de nos clients (retail, maintenance, énergie, télécommunication, pharmaceutiques, etc.).
Fort de ce succès, leur usage en est donc désormais généralisé, notamment dans 1) l’évaluation de nos modèles de prévisions (pour sélectionner les modèles les plus adaptés à nos clients) et 2) dans l’optimisation du paramétrage de nos algorithmes (en nous appuyons sur nos « digital twins » pour simuler finement leurs impacts tant financiers qu’opérationnels).
Qu’en est-il de votre entreprise ? Les métriques en place visent-elles bien une précision « opérationnellement parfaite »? Quelles perspectives ces nouvelles métriques vous ouvrent-elles ?
Dans nos prochains articles, nous reviendrons plus en détail sur les nouveaux usages qu’autorise les métriques de « Forecast Impact ».
Replay de notre webinar "Comment transformer votre prévision en une prévision orientée business ?"

4 axes à surveiller pour l'optimisation logistique
Comment et pourquoi privilégier une optimisation logistique ?
En premier lieu, qu’entendons-nous par optimisation logistique ? Optimiser, c’est donner les meilleures conditions de fonctionnement à quelque chose.
Optimiser sa chaîne logistique, ou supply chain, c’est donc mettre en œuvre des moyens et des processus lui permettant d’être plus performante dans son ensemble.
C’est aussi adopter des méthodes et un fonctionnement responsable et écologique, soucieux de l’environnement et de l’impact de nos actions sur celui-ci.

Un avantage opérationnel
Dans un monde désormais ultra-connecté, où la demande de biens et de services est mondiale, les chaînes logistiques sont de plus en plus sollicitées, les acteurs et intermédiaires de plus en plus nombreux, entraînant une hausse des coûts de stockage et de transports.
La concurrence est telle que les supply chain, autrefois considérées comme secondaires, attirent d’avantage l’attention des décisionnaires au sein des organisations de part leur importance croissante.
Ainsi, posséder une chaîne logistique bien optimisée facilite l’ensemble des opérations et permet une meilleure gestion de la supply chain, en apportant une vue d’ensemble de celle-ci aux professionnels.
L’optimisation permet d’assurer la qualité des produits, de maîtriser les coûts, d’éviter le gaspillage, et surtout de réduire les délais de livraison, un des facteurs les plus importants pour le client final, après le prix.
C’est donc devenu un véritable avantage compétitif pour les entreprises. On juge désormais de nombreuses organisations à la qualité de leur supply chain.
Les bonnes technologies
Optimiser sa chaîne logistique, c’est aussi l’adapter aux nouvelles technologies, aux fonctionnalités et avantages qu’elles représentent et peuvent offrir.
Grâce aux données, récupérées sur des points de collectes de plus en plus nombreux grâce à L’IoT (Internet of Things) la gestion de la supply chain est facilitée, les échanges de toutes ses informations permettent une bonne communication entre les différents acteurs logistiques.
Les supply chains et leurs gestions se digitalisent, comme le reste du monde.
Des très nombreuses entreprises proposent aujourd’hui des solutions logicielles afin d’améliorer et faciliter la gestion des flux logistiques, ainsi que la gestion des stocks.
Que cela soit via des interfaces plus ergonomiques, avec des indicateurs clés de performance, à travers des algorithmes de machine learning et d’intelligence artificielle, ou encore via des entrepôts connectés, les données sont de plus en plus fiables, précises et peuvent être surveillées en temps-réel.
Ces nouvelles technologies présentent donc des atouts majeurs, à forte valeur ajoutée pour les entreprises en quête d’optimisation de leur chaîne logistique.
La crise sanitaire et la croissance exponentielle des achats à distance n’a fait que confirmer cette tendance de digitalisation des entreprises et de leurs chaînes d’approvisionnement.
Quels sont les risques d’un manque d’optimisation logistique ?
• La rupture de stock, entraînant l’incapacité de répondre à la demande, ou au contraire posséder trop d’inventaire, des coûts de stock élevés et un possible gaspillage.
• Le surstock, posséder trop d’inventaire résultant en des coûts de stock élevés et un possible gaspillage des marchandises.
• Des retards de livraison, ayant pour conséquence des délais de production et une insatisfaction client.
• De ne pas d’adapter aux nouvelles technologies par volonté d’effectuer des d’économies de trésorerie.
4 axes à surveiller pour une supply chain optimisée
LA QUALITÉ DES PRODUITS
Assurer la meilleure qualité possible pour ses produits : face à une multitude de choix, accessibles en quelques clics, le client cherche de plus en plus des produits de bonne qualité.
LES LOGICIELS UTILISÉS
Utiliser un logiciel de gestion centralisé : les ERP permettent d’avoir une vue globale de toutes les facettes liées au business de l’entreprise. Ces logiciels permettent de rassembler tous les secteurs d’une organisation et leurs datas, offrant une visibilité cohérente et facilitant la gestion.
L’AUTOMATISATION DE LA SUPPLY CHAIN
Automatiser votre supply chain : l’optimisation de votre supply chain dépend en partie de son efficacité. L’automatisation des commandes, particulièrement pour les entrepôts possédant des milliers de références est devenue aujourd’hui indispensable.
TRANSPARENCE ET VUE GLOBALE SUR LES OPÉRATIONS
Adopter une supply chain transparente : avoir une vue d’ensemble sur sa chaîne logistique est primordiale dans la route vers son optimisation. La traçabilité des produits et la coopération entre les différents de maillon de la chaîne est nécessaire pour garantir au client le meilleur service possible.

Comment bien planifier ses commandes ?
Pendant que la plupart des Supply Chains en ont besoin, la planification des commendes et des stocks est particulièrement importante dans le retail.
Les détaillants et les entreprises concernés par la forte rotation de leurs produits de la grande distribution continuent à élargir leur gamme de produit.
Bien que cela propose aux consommateurs plus de choix grâce à la gestion de la chaîne d’approvisionnement, la planification des stocks pose de nombreux challenges.
Etant donné les contraintes d’espace, les préférences du client et la rentabilité, les détaillants doivent mettre en place la planification des stocks.
La planification des stocks consiste à sélectionner la bonne gamme de produit ainsi que les bonnes quantités pour répondre correctement à la demande du marché.
La première dimension est “la largeur”, qui fait référence au nombre de variétés de produits différents. La seconde dimension est “la profondeur”, qui représente les différents choix en ce qui concerne les marques d’une et même variété ou catégorie
Qu’est-ce qui a changé ?
Avec la situation actuelle, les détaillants doivent prendre en compte les questions suivantes :
Comment utiliser au mieux l’inventaire existant (dans les magasins et en transit) ?
Y a-t-il des modifications à réaliser sur les commandes établies ?
Quel est le meilleur plan avec l’inventaire existant qui va maximiser le profit ?
Les mesures à prendre pour une bonne planification des commandes

Faire le compte des inventaires, particulièrement les produits périssables.

Diminuer la largeur (nombre de variétés) de la gamme de produits.

Utiliser l’IA pour avoir la meilleure gamme de prix et de produits.

Se diversifier vers la distribution omni-channel.

Gestion automatisée des stocks : Vekia un outil indispensable.
La gestion des stocks est un facteur essentiel de réussite pour votre entreprise. En l’automatisant, vous pourrez optimiser vos prévisions et gagner du temps sur les tâches répétitives à faible valeur ajoutée.
Grâce à la solution Vekia de gestion automatisée des stocks, vous réduisez les coûts et les pertes de temps liés à la supply chain.
La gestion des stocks : un facteur de réussiste
Pour assurer la pérennité et le développement de votre activité, vous devez prendre en compte de nombreux facteurs. La gestion des stocks est l’un d’entre eux.
Elle joue un rôle essentiel car elle impacte à la fois la satisfaction des clients, la capacité de production et, bien sûr, la santé financière de l’entreprise.
La gestion des stocks peut se composer de divers éléments : les marchandises, les matières premières, les produits finis et semi-finis ou encore les produits de conditionnement (emballages, palettes, cartons, etc.). Cela demande de réaliser des prévisions qui tendent au maximum vers le besoin futur de l’entreprise.
Pour cela, il existe plusieurs méthodes de gestion des stocks. Toutefois, il est important de noter que l’automatisation des stocks n’est pas là pour remplacer l’approvisionneur.
Cela va simplement le soulager dans ses tâches répétitives.
L’humain conserve la responsabilité de prise de décision et l’outil vient faciliter son travail en traitant une grande quantité de data.
Voici quelques exemples de méthodes de gestion des stocks.
Gestion automatisée des stock : la méthode du “juste à temps”
Cette méthode repose sur le paramétrage d’alertes qui engagent le réapprovisionnement lorsque le stock d’un produit arrive à une quantité donnée. Dans ce cas, l’entreprise va commander la même quantité d’articles à chaque fois que l’alarme se déclenche.
De cette façon, vous pouvez limiter l’espace de stockage au maximum.
Toutefois, cette méthode du “juste à temps” ne permet pas de prévoir des variations dans la demande. En commandant toujours la même quantité, on peut se retrouver en rupture de stock si la consommation augmente.
La méthode de réapprovisionnement calendaire
Il s’agit de la méthode de gestion des stocks la plus simplifiée. Elle consiste à commander à une date fixe la même quantité de produits (ou presque).
Dans ce cas, vous estimez donc que vous voulez recevoir X produits tous les X temps. Vous pouvez ainsi réguler vos réapprovisionnements à l’année et négocier une réduction du prix unitaire avec votre fournisseur.
Vous vous en doutez, cette méthode calendaire ne permet de prévoir aucune fluctuation des besoins. Vous pourrez donc connaître des ruptures de stocks ou à l’inverse des périodes de surstockage.
La méthode de recomplètement des stocks
La gestion des stocks de recomplètement est l’inverse de la méthode du “juste à temps”. Cette fois, la date de commande est fixe mais la quantité varie en fonction de l’état du stock.
Par exemple, si vous avez vendu 50 produits depuis la dernière commande, vous recevrez un réapprovisionnement de 50 articles.
Là aussi, cette méthode ne permet pas de prévoir une baisse ou une augmentation de la demande. Vous pouvez donc vous retrouver avec trop ou pas assez de stocks.
Si votre activité n’est pas régulière, cette méthode n’est pas adaptée.
La gestion des stocks grâce à l’analyse prédictive
Vous l’aurez compris, les 3 méthodes précédentes présentent le même problème. Elles ne prennent pas en compte une possible évolution de vos besoins.
Grâce au développement des Big Data et du Machine Learning, il est possible de réaliser des analyses prédictives extrêmement fiables. Celles-ci prennent en compte à la fois la demande mais aussi la variabilité de celle-ci, afin d’ajuster les stocks de sécurité de manière fine.
Avec notre solution de gestion automatisée des stocks, les prévisions sont définies grâce à des algorithmes se basant sur toutes les données de votre activité.
Grâce aux probabilités, il est possible d’établir des scénarios plus ou moins probables et d’ajuster le réapprovisionnement en fonction de ces prévisions.
Pourquoi faire confiance à la gestion automatisée des stocks de Vekia ?
Afin d’automatiser vos approvisionnements de façon efficace, Vekia s’appuie sur 4 fonctionnalités essentielles. Tout d’abord, la prévision de la demande est calculée par nos algorithmes de Machine Learning.
Ensuite, les commandes intelligentes permettent de calculer chaque jour vos besoins en réapprovisionnement de façon autonome.
Le tableau de bord de la solution Vekia permet de profiter d’une vue d’ensemble de votre réseau logistique en temps réel. Vous pouvez à la fois utiliser des indicateurs standards mais également des indicateurs personnalisés. Le tableau de bord peut également vous envoyer des alertes en cas de besoin.
Enfin, l’accès au catalogue des articles et des entités permet de consulter en temps réel toutes les informations concernant vos stocks. Chaque produit possède sa fiche d’informations.
Vous y retrouvez ses conditions d’achat, plusieurs statistiques et les prévisions qui le concernent. Il est également possible de visualiser rapidement l’ensemble des commandes en cours pour cet article.
Globalement, la solution Vekia va permettre de récupérer un grand nombre de données, de réaliser des prévisions et de calculer le réapprovisionnement en fonction.
Notre outil se veut à la fois simple à utiliser et à mettre en place, agile et précis.
N’attendez plus pour adopter la gestion automatisée des stocks avec Vekia.

Machine Learning et supply chain : quel rôle joue-t-il dans vos entreprises ?
Le Machine Learning est considéré comme une branche de l’intelligence artificielle puisqu’il permet aux ordinateurs d’apprendre de façon autonome.
Grâce à l’analyse de la Big Data, les systèmes de Machine Learning sont capables de concevoir des algorithmes sans intervention de l’Homme au préalable.
Découvrez notre définition du Machine Learning.

Définition du Machine Learning : l’apprentissage automatique grâce au Big Data
Dans tous les domaines de notre vie, la collecte de données est bien présente. Elle permet d’alimenter des bases de données gigantesques appelées le Big Data.
Celui-ci est essentiel au bon fonctionnement du Machine Learning. C’est cette énorme quantité d’informations qui va permettre au système de construire des algorithmes de manière autonome.
En se basant sur le Big Data, sur des statistiques ou encore sur des regroupements d’informations, l’ordinateur va être capable de réaliser des prédictions de façon précise et rapide. Une fois l’apprentissage terminé, il aura défini des algorithmes capables de traiter l’information d’une certaine manière pour atteindre un objectif donné.
Le Machine Learning s’oppose aux programmes traditionnels où les algorithmes sont définis par l’Homme. Dans ces programmes classiques, c’est l’Homme qui demande au système de fonctionner de telle manière si tel événement se présente.
En Machine Learning, le système le devine tout seul et s’améliore avec le temps, au fur et à mesure qu’il expérimente et traite l’information.

Les avantages du Machine Learning
Le Machine Learning, grâce à son caractère autonome, présente de nombreux avantages. Ces atouts peuvent s’appliquer à une multitude de secteurs d’activité. Le premier avantage est qu’il permet de traiter une grande quantité de données très rapidement. Grâce à cela, il pourra formuler des prédictions précises.
Ces prédictions peuvent être utilisées dans les domaines de la santé, des finances, de la supply chain ou encore de la maintenance industrielle.
De plus, le Machine Learning sera capable d’améliorer et de personnaliser vos actions en fonction du comportement de l’utilisateur (comportement d’achat, réaction aux actions de communication, etc.).
En somme, le Machine Learning maximise de manière globale les performances de votre activité. D’une part, il augmente vos ventes grâce à la personnalisation de la relation client. D’autre part, il optimise votre organisation interne en réalisant des prédictions précises et rapides.
Les différents algorithmes en Machine Learning
Dans le domaine du Machine Learning, on distingue 3 typologies d’algorithmes : l’apprentissage par renforcement, l’apprentissage supervisé et l’apprentissage non supervisé.
L’apprentissage par renforcement
Le premier type de Machine Learning est l’apprentissage par renforcement. Celui-ci s’appuie sur l’atteinte d’un objectif, par n’importe quel moyen. La machine est donc encouragée à réaliser un objectif donné comme par exemple gagner une partie d’échecs. En fonction de ses résultats, elle sera récompensée ou pénalisée.
Ce système est particulièrement utilisé dans les domaines du jeu et du e-sport. Cela a permis à des ordinateurs de gagner contre les plus grands joueurs du monde, notamment aux jeux d’échecs et de dames.
L’apprentissage supervisé
L’apprentissage supervisé consiste à aiguiller légèrement le système lors de son entraînement en caractérisant les données qui lui sont envoyées. Dans ce cas, on va indiquer au système ce qu’il doit chercher dans ces données afin qu’il soit ensuite capable de le faire lui-même.
Parmi les algorithmes d’apprentissage supervisé, on distingue ceux réalisant des prédictions numériques (algorithmes de régression) et ceux réalisant des prédictions non-numériques (algorithmes de classification).
L’apprentissage non-supervisé
Comme son nom l’indique, il s’agit ici de l’inverse de l’apprentissage supervisé. Dans le cas d’un apprentissage non-supervisé, la machine traite des données brutes, sans aucune indication. Elle va alors chercher à regrouper les données pour ensuite en dégager des tendances.
Ici, on retrouve 3 types d’algorithmes :
- les algorithmes d’association qui vont trouver des liens entre les données
- les algorithmes de clustering qui vont définir des groupes homogènes d’objets
- et les algorithmes de réduction dimensionnelle qui vont permettre d’extraire certaines caractéristiques des données.

Les différents usages du Machine Learning
Comme dit précédemment, les avantages du machine learning en font un outil intéressant pour de nombreux secteurs d’activités. Dans le domaine de l’IT, il est particulièrement apprécié pour optimiser le fonctionnement des moteurs de recherche (Google) et de recommandations (sur YouTube, par exemple). Il améliore également les algorithmes des réseaux sociaux et le fonctionnement des assistants vocaux.
Dans l’industrie, on retrouve l’utilisation du machine learning dans la gestion de la maintenance mais aussi dans le secteur automobile avec les voitures autonomes, par exemple. Il est utilisé dans le secteur médical pour le traitement des images de radiographies ainsi que dans le traitement du langage et la traduction.
Bien sûr, pour certains usages, le Machine Learning présente des failles. Certaines entreprises ont par exemple tenté d’utiliser ce système dans leur processus de traitement des CV. Le Machine Learning s’appuyant sur les caractéristiques des employés actuels, il avait tendance à creuser les discriminations déjà existantes.
Le Machine Learning dans le secteur de la Supply Chain
Grâce à la transformation digitale des entreprises, il est possible de collecter depuis quelques années un grand nombre de données concernant la logistique et la supply chain. Cela permet de créer une base de données suffisamment importante pour alimenter un système de Machine Learning.
Comme expliqué précédemment, l’un des principaux avantages est que cela permet de définir, précisément et rapidement, des prévisions à partir d’un grand nombre de données. Il est donc possible d’utiliser ces prédictions pour améliorer la gestion de vos stocks.
C’est sur ce principe de Machine Learning que se base la solution Vekia.